Met zelflerende modellen kunnen voorspellingen worden verklaard
Voor zijn promotieonderzoek creëerde Dennis Collaris tools om de output van AI-modellen te verklaren.

Zelflerende computermodellen kunnen waardevol zijn voor bijvoorbeeld spraakherkenning, fraudedetectie en het inschatten van medische risico’s. Maar onder meer het toeslagenschandaal laat zien dat grote voorzichtigheid geboden is: hoe een model tot een bepaalde conclusie komt, moet volgens de wet dan ook altijd uitlegbaar zijn. Om data-experts daarbij te helpen, ontwikkelde promovendus Dennis Collaris interactieve visualisatietools die inzicht bieden in de ‘gedachtegang’ van kunstmatig intelligente modellen.
“Het neemt een beetje onze wereld over”, zegt Dennis Collaris over kunstmatige intelligentie (vaak afgekort tot AI, van de Engelse term Artificial Intelligence). En dat meent hij best serieus. “Je kunt het zo gek niet bedenken of er wordt AI voor ingezet, met name om voorspellingen te doen.” Vaak zijn de toepassingen relatief onschuldig, zoals in spraakherkenning of automatische vertalingen. “Als daarin een klein foutje wordt gemaakt, zijn de gevolgen zelden wereldschokkend. Maar er zijn natuurlijk ook toepassingen, bijvoorbeeld fraudedetectie, waarbij een voorspelling van een AI-systeem enorme gevolgen kan hebben voor mensen. Hoe ernstig de gevolgen kunnen zijn als je onterecht als fraudeur wordt aangemerkt, is wel duidelijk geworden door het toeslagenschandaal.”
De Europese privacywetgeving AVG stelt daarom dat altijd uit te leggen moet zijn hoe computermodellen tot een bepaalde aanbeveling komen. Dat is bij een zelflerend AI-systeem echter zeer lastig: het is de spreekwoordelijke ‘black box’ die op basis van een berg gegevens een antwoord uitspuugt, waarvan niet zomaar te achterhalen is hoe het tot stand is gekomen. De crux is namelijk dat het computermodel geen vastomlijnd stappenplan volgt, maar gaandeweg zelf heeft uitgevonden welke (combinaties van) kenmerken van - bijvoorbeeld - potentiële verzekeringsnemers iets zeggen over de kans dat ze van plan zijn om te frauderen.
Motivatie
Het komt erop neer dat zo’n zelflerend model wel aantoonbaar nuttige aanbevelingen doet, maar daar geen motivatie bij geeft. Terwijl zo’n motivatie wel vereist is om iemand af te wijzen voor een verzekering, of voor het starten van een fraudeonderzoek. ‘Computer says no’ is daarvoor geen geldige reden. “Bij een verzekeraar als Achmea, waarmee ik voor mijn onderzoek heb samengewerkt, kost het data-experts ontzettend veel werk om hun voorspellingsmodellen te verklaren”, legt Collaris uit. De Eindhovenaar studeerde Web Science aan TU/e-faculteit Mathematics and Computer Science en studeerde af binnen de visualisatiegroep van hoogleraar Jack van Wijk, die hem vervolgens vroeg om te blijven voor een promotietraject.
Om uit te vinden welke strategie een computermodel heeft gevolgd, is het overzichtelijk in beeld brengen van de gebruikte - en verwerkte - data van essentieel belang. Collaris ontwikkelde daarom twee interactieve softwaretools, ExplainExplore en StrategyAtlas, die gebruikers een inkijkje bieden in de ziel van zelflerende modellen.
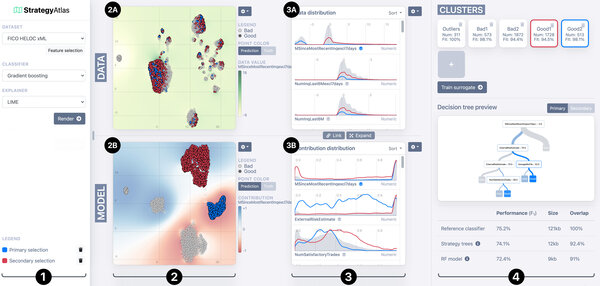
Groepen
StrategyAtlas helpt onder meer bij het zoeken naar patronen in de data, en laat met name zien hoe het model personen indeelt in verschillende groepen (zie hieronder). In plot 2A staat elk bolletje voor een individu, en staan personen die qua eigenschappen op elkaar lijken dicht bij elkaar. In 2B zijn diezelfde individuen weergegeven, maar dan ingedeeld op basis van de gewichten die het model aan deze eigenschappen heeft toegekend. Elke groep punten in deze visualisatie komt overeen met een ‘modelstrategie’ die een model gebruikt om een voorspelling te doen: het model gebruikt ongeveer dezelfde eigenschappen voor alle individuen in die groep. De gewichten zijn afhankelijk van het doel van het model (bijvoorbeeld inschatten of een klant een fraudeur is of een potentiële wanbetaler).
Een zelflerend model kijkt vaak heel anders naar de wereld dan je misschien zou verwachten, benadrukt de promovendus. Dat blijkt duidelijk uit de visualisaties in de StrategyAtlas. “Je ziet dat de rode en de blauwe groep, die door het model als heel verschillend worden gezien, dat op basis van de inputdata niet lijken te zijn. In 2A staan blauw en rood namelijk helemaal door elkaar.”
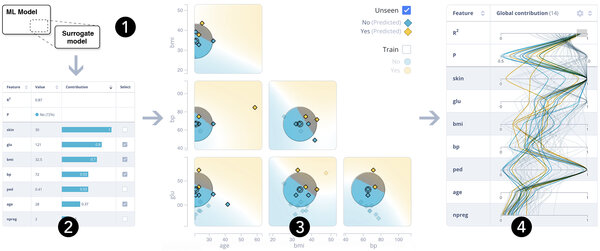
Collaris’ andere softwaretool, ExplainExplore, laat heel duidelijk zien hoe zwaar een bepaalde eigenschap voor het model meetelt bij het bepalen van een voorspelling. “Dat noemen we de ‘feature contribution’.” Als voorbeeld noemt hij het voorspellen van de kans op suikerziekte (zie in de afbeelding hieronder). Voor elk individu laat de software zien hoe zwaar elke eigenschap heeft meegewogen voor de voorspelling (links, in dit geval: 28 procent kans op suikerziekte). Huiddikte (‘skin’), bloedsuikerwaarde (‘glu’) en bmi wogen het zwaarst. “Als er uit deze analyse onverwachte feature contributions naar voren komen, kan dit een reden zijn om het model nog eens kritisch onder de loep te nemen, maar in theorie kan een onverwacht resultaat natuurlijk ook tot interessante medische inzichten leiden.”
Rechts zijn de ‘feature contributions’ voor andere individuen uit de dataset weergegeven. Daaruit blijkt bijvoorbeeld dat het model in het algemeen weinig belang stelt in het aantal zwangerschappen dat een individu heeft doorgemaakt, maar ook dat er een opvallend grote variatie is in hoe zwaar de ‘pedigree’ (een maat voor hoe vaak de ziekte in de familie voorkomt) meetelt. In het midden, tot slot, is weergegeven hoe robuust het model is voor kleine aanpassingen in de waarden. “Als huiddikte zo belangrijk zou zijn, dan verwacht je niet dat die huiddikte opeens nauwelijks uitmaakt voor de voorspelling als de huid net iets dikker of dunner is.” De plotjes in het midden geven daar informatie over en zeggen dus iets over de betrouwbaarheid van het model.
PhD thesis
Op de omslag van zijn proefschrift staat ook een diagram met drie balkjes, dat Collaris maakte met ExplainExplore. Voor de grap leerde hij een computermodel voorspellen tot welke categorie een technisch document behoort, op basis van zeventien eigenschappen. Vervolgens voerde hij de pdf van zijn eigen proefschrift in. En ja hoor: de uitkomst was: ‘PhD Thesis’. Dat wist hij natuurlijk al, maar nu weet hij ook waarom. ”De belangrijkste ‘feature contributions’ bleken het aantal pagina’s en de maximale hoogte en breedte van de afbeeldingen. Dat is dus blijkbaar wat mijn proefschrift tot een proefschrift maakt!”
Dennis Collaris verdedigt op 8 juli zijn proefschrift bij de faculteit Mathematics & Computer Science. Titel van PhD-thesis: “Interactive visualization for interpretable machine learning”. Promotors: Jack van Wijk en Mykola Pechenizkiy.
Bron: Cursor.
Mediacontact
Meer over AI


Het laatste nieuws


